一种在拥挤环境中改进机器人导航的新方法
尽管机器人在过去几年中变得越来越先进,但它们中的大多数仍然无法可靠地在非常拥挤的空间中导航,例如城市环境中的公共区域或道路。然而,要在未来的智慧城市中大规模实施,机器人需要能够可靠、安全地在这些环境中导航,而不会与人类或附近的物体发生碰撞。
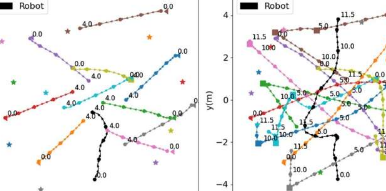
萨拉戈萨大学和西班牙阿拉贡工程研究所的研究人员最近提出了一种新的基于机器学习的方法,可以改善室内和室外拥挤环境中的机器人导航。在arXiv服务器上预发表的一篇论文中介绍的这种方法需要使用内在奖励,本质上是AI代理在执行与其试图完成的任务不严格相关的行为时收到的“奖励”。
“自主机器人导航是一个悬而未决的问题,尤其是在非结构化和动态环境中,机器人必须避免与动态障碍物发生碰撞并到达目标,”进行该研究的研究人员之一DiegoMartinezBaselga告诉TechXplore.“深度强化学习算法已被证明在成功率和达到目标的时间方面具有很高的性能,但仍有很多需要改进的地方。”
MartinezBaselga和他的同事介绍的方法使用内在奖励,奖励旨在增加代理人探索新“状态”(即与其环境的交互)的动机或降低给定场景中的不确定性水平,以便代理人能够更好地预测他们行为的后果。在他们的研究中,研究人员特别使用这些奖励来鼓励机器人访问其环境中的未知区域并以不同的方式探索其环境,以便它能够随着时间的推移学会更有效地导航。
“最先进的用于人群导航的深度强化学习的大部分工作都集中在改进网络和机器人感知的处理上,”MartinezBaselga说。“我的方法研究如何在训练期间探索环境以改进学习过程。在训练中,机器人不会尝试随机动作或最佳动作,而是尝试做它认为可以从中学到更多东西的事情。”
MartinezBaselga和他的同事使用两种不同的方法评估了使用内在奖励来解决机器人在拥挤空间中导航的潜力。其中第一个集成了所谓的“内在好奇心模块”(ICM),而第二个基于一系列称为随机编码器的算法以进行有效探索(RE3)。
研究人员在CrowdNav模拟器上运行的一系列模拟中评估了这些模型。他们发现,他们提出的两种整合内在奖励的方法优于先前开发的用于在拥挤空间中进行机器人导航的最先进方法。
将来,这项研究可以鼓励其他机器人专家在训练他们的机器人时使用内在奖励,以提高他们应对不可预见情况并在高度动态环境中安全移动的能力。此外,MartinezBaselga和他的同事测试的两个基于奖励的内在模型很快就可以在真实机器人中进行集成和测试,以进一步验证它们的潜力。
“结果表明,应用这些智能探索策略,机器人学习速度更快,最终学到的策略更好;并且它们可以应用于现有算法之上以改进它们,”MartinezBaselga补充道。“在我接下来的研究中,我计划改进机器人导航中的深度强化学习,使其更安全、更可靠,这对于在现实世界中使用它非常重要。”
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
【萝卜的药用功效和作用】萝卜,作为日常生活中常见的蔬菜之一,不仅味道清脆、营养丰富,还具有多种药用价值...浏览全文>>
-
【萝卜的家常做法】萝卜是一种非常常见的蔬菜,不仅价格实惠,而且营养丰富,适合多种烹饪方式。无论是炖、炒...浏览全文>>
-
【萝卜的功效与作用与主治】萝卜是一种常见的根茎类蔬菜,广泛种植于世界各地,具有丰富的营养价值和多种药用...浏览全文>>
-
【萝卜刀怎么玩儿】“萝卜刀”作为一种近年来在网络上逐渐流行的玩具,因其独特的玩法和趣味性吸引了大量年轻...浏览全文>>
-
【萝卜刀是什么】“萝卜刀”是近年来在网络上迅速走红的一种玩具,因其外形酷似胡萝卜而得名。它不仅是一种简...浏览全文>>
-
【萝卜刀的危害】近年来,“萝卜刀”作为一种新型玩具,因其造型独特、操作简单而受到部分青少年的喜爱。然而...浏览全文>>
-
【萝卜车多少钱一辆】“萝卜车多少钱一辆”是许多消费者在选购新能源汽车时最关心的问题之一。萝卜车,即“萝...浏览全文>>
-
【10月14日是什么纪念日】10月14日是每年都会被不同国家和地区以不同方式纪念的日子。这一天在历史、文化、政...浏览全文>>
-
【10月14号是什么星座的】10月14日是阳历日期,对应的星座是天秤座(9月23日—10月22日)。天秤座的人通常性格...浏览全文>>
-
【10月13日五行穿衣】10月13日,根据中国传统五行理论,结合当天的天干地支与五行属性,可以为不同体质和命理...浏览全文>>